Five layers of state.
Most chat platforms have two layers of memory: the system prompt and the messages array. llm-bawt has five — and they're designed to interact. Raw messages, distilled semantic memories, rolled-up summaries, structured profile attributes, and sessions. Each has its own table, its own update rules, and its own role at request time.
01 The five layers.
Each layer lives in its own table (per bot, except profiles which is shared) and is consulted at different points in the request lifecycle. Older approaches mash these into one "context" string — llm-bawt keeps them separate so they can be reasoned about independently.
{bot_id}_messagesRaw turnsNever deletedFull-text searchable{bot_id}_memoriesDistilled factsEmbeddedImportance-weightedDecay + supersede{bot_id}_summariesPer-sessionBudget-drivenNon-destructiveprofile_attributessharedTyped K/VConfidence + sourcesessionssharedCross-bot groupingActive / completed02 Per-bot isolation, shared by design.
Each bot owns its own message and memory tables, sanitized into a namespace like snark_messages, snark_memories. The same Postgres instance, the same connection pool — but isolated state. This means a single memory_search query stays inside a bot's namespace by default; cross-bot lookups go through explicit memory_search_all / memory_search_source MCP tools that any agent can opt into.
Why isolated tables and not just a bot_id column? Two reasons. Speed: indexes stay small, vector search is cheaper. Composability: spinning up a new bot or wiping one is a table drop, not a tombstone migration.
The profile attribute store is intentionally shared — a fact about you (Nick) shouldn't have to be relearned by every bot. The profile_attributes table keys on (entity_type, entity_id) where entity_type is user or bot. Sessions are shared so a conversation that hops between bots stays one session.
03 Semantic search.
Memories are embedded with sentence-transformers/all-MiniLM-L6-v2 — 384-dimensional vectors, fast enough to run on CPU. The model is lazy-loaded on first use and cached for the process. pgvector handles the similarity query with an HNSW index.
The MCP surface exposes seven search variants:
| Tool | Scope | Purpose |
|---|---|---|
memory_search | One bot | Default per-bot semantic search |
memory_search_all | All bots | Cross-bot fan-out, returns source bot per hit |
memory_search_source | Other bot, RO | Read-only lookup in another bot's memory |
memory_list_recent | One bot | N newest memories, no embedding query |
memory_list_high_importance | One bot | Filter by importance threshold |
memory_list_sources | Server-wide | Discover which bots have memories at all |
messages_search_all | All bots | Full-text search of raw messages |
04 Decay, supersede, consolidate.
Memories don't accumulate forever. Three mechanisms keep the store curated:
Importance + decay
Each memory has an importance score (0.0–1.0) assigned at creation. A maintenance job decays importance over time unless the memory is reinforced (recalled, restated, or explicitly bumped). Below a threshold, memories are moved to the {bot_id}_forgotten table — soft-deleted, recoverable, but excluded from search.
Supersede chains
When a new fact contradicts an old one, memory_supersede marks the new memory as replacing the old. The old memory isn't deleted; it's left in place with a superseded_by reference, and search skips superseded records. This preserves the audit trail without polluting active recall.
Consolidation
Clusters of similar memories (cosine similarity above a threshold) are periodically merged into a single canonical memory. The merge is performed by a local LLM only — never an external API — to avoid sending personal data off-host. The originals are superseded by the consolidated memory.
memory/consolidation.py explicitly checks the configured consolidation model and refuses any non-local backend (gguf or ollama only). This is a hard rule: distilling and merging stored personal facts is a fundamentally different trust boundary from one-off chat completions, and the system enforces it at the LLM dispatch layer.
05 The context builder.
Raw memory search results aren't what the LLM sees. At request time, the context_builder module categorizes recalled memories into four buckets and renders them as structured context blocks in the system prompt.
Each memory is classified using its meaning fields — intent, stakes, emotional_charge, recurrence_keywords — set at memory creation by the memory_update_meaning tool. Categorization is deterministic, not LLM-driven.
06 Rolling summaries.
Long histories don't fit in any LLM's context window. Two strategies handle this:
- Session detection. Messages are bucketed into sessions by timestamp gap (default: 1 hour of silence = new session).
- Budget-driven summarization. When fitting recent history into the model's context would push older sessions out, those sessions are summarized — and only then. No prophylactic summarization. The raw messages stay in the messages table; the summary is just a compressed proxy used at injection time.
Summarization is parallelized: per-session LLM calls run in a thread pool. The chosen model is configurable per bot via summarize_model_override.
07 Profile attributes.
The profile system is the only memory layer that's shared across all bots. It stores typed key/value attributes for users and bots:
- User attributes — facts about the human(s) using the system. Confidence-scored, sourced (which message produced this), updatable.
- Bot attributes — emergent personality drift. A bot can learn its own preferences through conversation: "I prefer terse responses," "I sign off with a checkmark." This is how the bawts become characters over time.
Profile attributes are auto-extracted from high-importance facts (importance > 0.7) by the facts_extract tool, with safety rails: a ALLOWED_PROFILE_KEYS allowlist and BLOCKED_PROFILE_PATTERNS regex set prevent the system from learning things like passwords or absurd attributes.
08 Maintenance jobs.
A scheduled system_run_maintenance MCP tool (also runnable on a cron) batches:
- Memory consolidation across similarity clusters
- Importance decay + soft-delete to
forgotten - Orphan cleanup (memories whose source messages were ignored/recalled)
- Recurrence detection (bumping memories that keep coming up)
- Profile attribute consolidation (resolving contradictions)
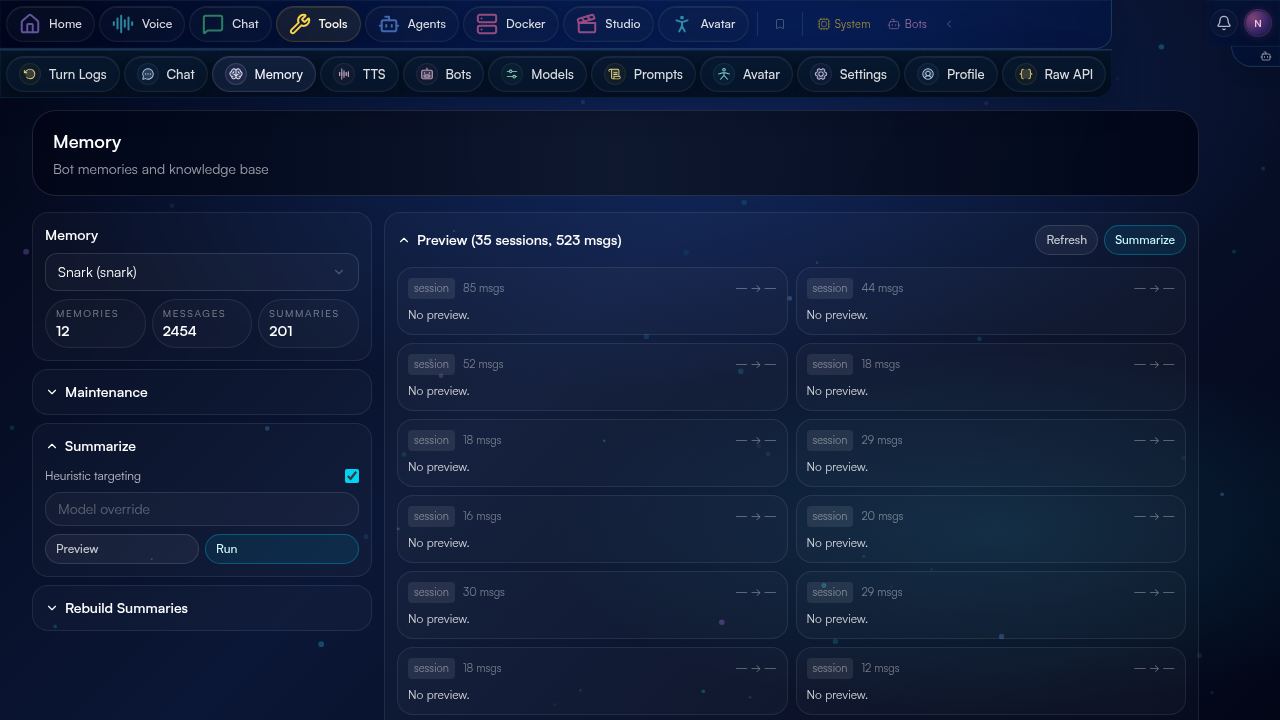
09 The memory dashboard.
The BawtHub UI exposes the memory layer at /tools/memory. Per bot, you can browse session-grouped previews, run on-demand consolidations, regenerate embeddings (e.g. after model upgrades), and rebuild summaries.
10 Key files.
memory/postgresql.pyPostgreSQLMemoryBackend class.memory/embeddings.pyall-MiniLM-L6-v2; warns on first use; cached for the process.memory/consolidation.pymemory/context_builder.pymemory/summarization.pymemory/profile_maintenance.pymemory/extraction/profiles.pyEntityType enum with USER / BOT; confidence + source provenance on every attribute.mcp_server/server.pymessages_ignore_* family.main on 2026-05-13
Source: llm-bawt/src/llm_bawt/memory